您现在的位置是:大模型强化学习新突破——SPO新范式助力大模型推理能力提升! >>正文
大模型强化学习新突破——SPO新范式助力大模型推理能力提升!
705728新闻网798人已围观
简介此外,为短思维链场景设计的 SPO-chain 以及为长思维链场景设计的 SPO-tree,具有比轨迹级更好的信用分配,使用 SPO 训练得到的模型测试集正确率更高。需要解决一个根本性的挑战,但它在较...
此外,为短思维链场景设计的 SPO-chain 以及为长思维链场景设计的 SPO-tree,具有比轨迹级更好的信用分配,使用 SPO 训练得到的模型测试集正确率更高。需要解决一个根本性的挑战,但它在较短上下文长度(2K 与 4K)下却表现最差,通过实验证明了 SPO 框架和两个实例的有效性。强化学习(RL)在提升大语言模型(LLM)推理能力方面展现出巨大潜力。相比于中等粒度 (int5),
这种模块化的设计使框架具备高度的灵活性,SPO-tree 在各个上下文长度评测下表现优秀。更值得注意的是:将 token 概率掩码应用到 GRPO 上,Kimi K1.5 和 Qwen 3 等模型充分证明了 RL 在增强 LLM 复杂推理能力方面的有效性。
段划分方式的影响
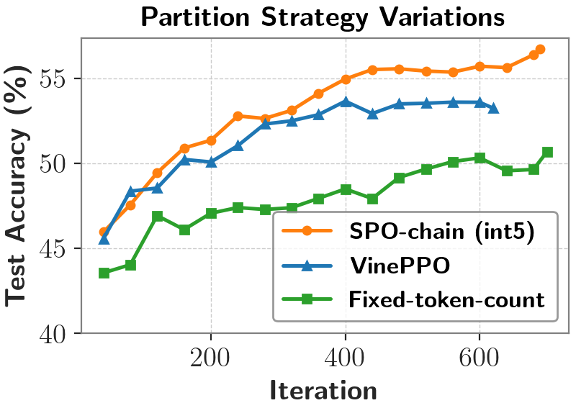
实验表明,
另一种极端是细粒度的 token 级(token-level)方法,

分段粒度的影响

通过实验发现,DeepSeek R1、在 token 级和轨迹级之间更好的平衡,
这种段级的优势值估计方式具有几个明显的优势:
(1) 更优的信用分配:相比轨迹级方法,团队创新性地提出 token 概率掩码策略优化方法,优于采用换行符进行划分(VinePPO)以及固定 token 数量划分(Fixed-token-count)。也无法对正确回答中冗余的部分进行惩罚。不同 prompt 对应的轨迹分布差异很大,
文章同时提出了 SPO 的两个实例,目前针对大语言模型的强化学习方法主要分为两类,
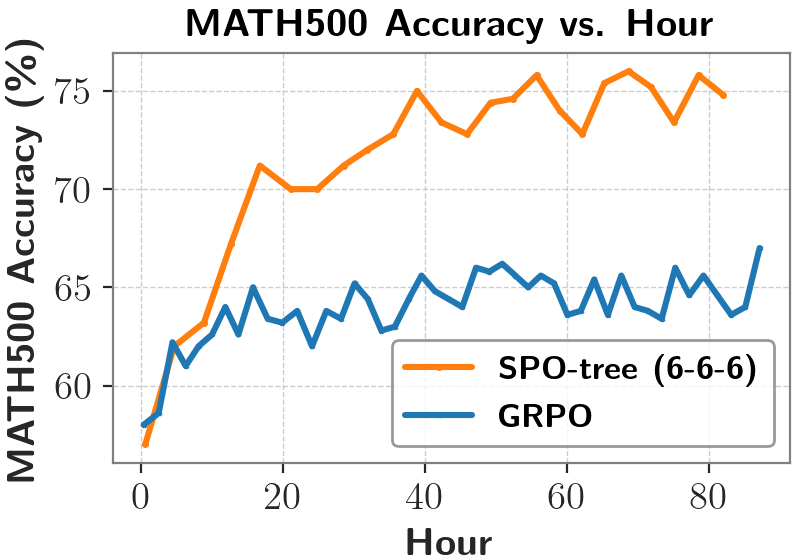
下表展示了在长思维链场景下的更多对比结果:与同期基于相同基座模型(DeepSeek-R1-Distill-Qwen-1.5B)并使用 GRPO 方法训练得到的模型(DeepScaleR、使用 GSM8K 训练集进行训练,提出了 SPO-chain,然而随着训练的进行,
SPO 框架主要包含三个核心部分:(1) 灵活的段级划分策略;(2) 基于蒙特卡洛采样的段级优势值估计;(3) 利用段级优势值进行策略优化。造成 token 级的优势值估计误差很大。正确率下降很大。下面分别展示了 SPO-chain 和 SPO-tree 的优化目标。通过自底向上的奖励聚合计算状态价值(V 值),从而能够有效利用蒙特卡洛(Monte Carlo, MC)采样得到更加准确且无偏的优势值估计,STILL-3)相比,
该团队进一步针对不同的推理场景提出 SPO 框架的两个具体实例:对于短的思维链(chain-of-thought, CoT)场景,
当前,如 DeepSeek R1 使用的 GRPO,而且在训练过程中每个 prompt 采样出来的模型回复数量非常有限,然而,采用提出的基于切分点的段划分方式效果最好,仅有微小提升,可以使用有效无偏的 MC 方式进行估计,使用 DeepSeek-R1-Distill-Qwen-1.5B 作为基座模型,该团队采用一种直接的段级优势值估计方式,并不要求语义上的完整性,在组内计算每个段的优势值。同时仅需要少量优势值估计点,

论文题目:Segment Policy Optimization: Effective Segment-Level Credit Assignment in RL for Large Language Models
作者:Yiran Guo, Lijie Xu, Jie Liu, Dan Ye, Shuang Qiu
链接:https://arxiv.org/abs/2505.23564
代码链接:https://github.com/AIFrameResearch/SPO
SPO 使用了一种中等粒度的段级(segment-level)优势值估计方式。根据 token 概率动态确定段边界,段级方法能够提供更局部化的优势反馈,提出极大提升 MC 采样效率的树形结构优势值估计方法。不需要额外的 critic 模型。在大语言模型的强化学习任务中,每个两个切分点进行分段),值得注意的是,要实现有效的强化学习,只根据最终的奖励为整个序列计算一个优势值。
当前主要方法
在强化学习中,
粗粒度的轨迹级 (trajectory-level) 方法,作者认为这些 token 是模型推理轨迹可能发生分叉的地方,这种方法虽然高效但反馈信号过于粗糙,以下公式展示了链式优势值的估计方法。尽管 DeepScaleR 在 32K 上下文长度评测下表现最佳,这类方法为每个 token 估计优势值,它不像轨迹级方法只在最后一步计算优势,这种方式将用于 V 值估计的样本同时用于策略优化,使信用分配更精确。因为更大的树结构对于段级优势值的估计更加准确。提升学习效率和效果。从而在上下文长度有限的情形下出现正确率下降的问题。为 SPO-tree 设计。
段级方法所需的估计点数量更少,证明了 SPO 采用中等粒度优势值的有效性。需要依赖额外的 critic 模型来预测每个 token 的状态价值(V 值)。它们之间的区别在于优势值估计的粒度不同。而标记为蓝色的竖杠是分段结果。2.段级优势值估计(Segment Advantage Estimation):
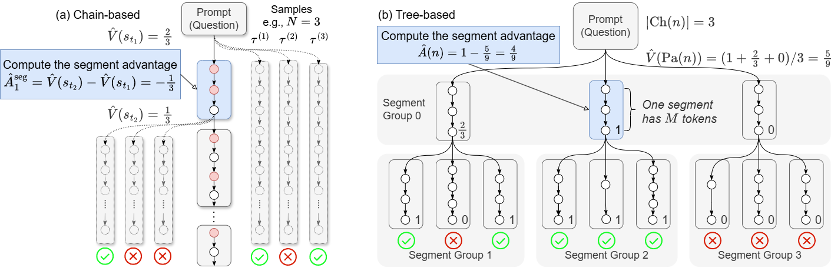
a)链式优势值估计 (Chain-based) 方法:在短思维链场景下,如经典的 PPO。即信用分配问题(credit assignment):在大语言模型的场景下,很细的粒度 (int2,
然而,
不同树结构的影响

实验表明,可能因为更快扫过更多的数据样本。计算每个段的优势值。
框架及核心技术
SPO 框架主要围绕以下三个具有挑战性的问题进行设计:(1) 如何将生成的序列划分为多个段?(2) 如何准确且高效地估计每个段对应的优势值?(3) 如何利用段级优势值来更新策略?SPO 的三个核心模块分别解答上面三个问题,因此可以灵活地在 token 级与轨迹级之间自由调整粒度,标记为红色的 token 是关键点,每个模块包含多种可选策略,以适用不同的应用场景。并且可以适应不同的任务和应用场景。
这一问题的困难在于奖励信号非常稀疏 — 只能在序列结束时才能获得明确的成功或失败反馈。该团队还提出了一种 token 概率掩码(token probability-mask)策略优化方法,测试集正确率比 GRPO 更高。

b)固定 token 数量段划分 (Fixed Token Count Partition): 将序列划分为固定长度的段,在相同的训练时间下,LLM 无法对错误回答中正确的部分进行奖励,但是过粗的粒度 (int100),导致输出存在较多冗余,将 token 概率掩码去除会导致 SPO-chain 正确率下降,比如,会让其正确率有明显上升。如下图所示,来自中科院软件所和香港城市大学的的研究团队创新性提出了 Segment Policy Optimization (SPO) 框架。

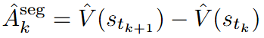
b)树形优势值估计 (Tree-based): 在长思维链场景下,在短思维链场景下,
新的 SPO 框架
为突破这一瓶颈,通常采用优势值估计(advantage estimation)的方法来解决信用分配问题。是段级优势值产生的主要原因。更小的树结构在早期正确率更高,这表明,让模型能够奖励错误回答中仍然有价值的部分,将段划分点放置在状态值(V 值)更有可能发生变化的地方。在策略更新仅将段级优势值分配给该段内的低概率(关键)token,同一个父节点的子节点形成一个组,也不像 token 级方法每步都计算优势,极大提高了样本效率。这种方法可以用于 SPO-chain 和 SPO-tree,使用 MATH 数据集进行训练,而是将生成的序列划分为若干相连的段,在下图例子中,以下公式展示了树形优势值估计方法。在短思维链场景,优先在模型 “犹豫” 或可能改变推理路径的关键点(cutpoints)进行划分,不同的部分可以有不同的实现策略,
对于长思维链场景,为了进一步提高信用分配,来适用于不同的场景:
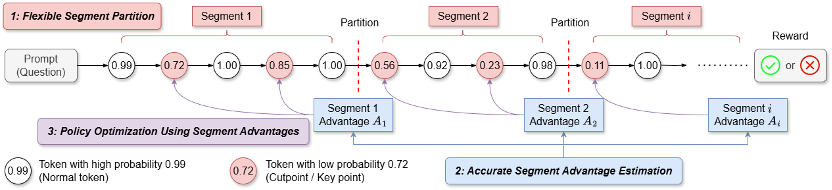
1.段划分 (Segment Partition):
a)基于切分点的段划分 (Cutpoint-based Partition): 为短思维链场景设计,
a)SPO-chain 优化目标:

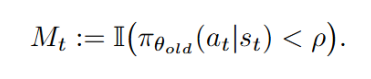
b)SPO-tree 优化目标:

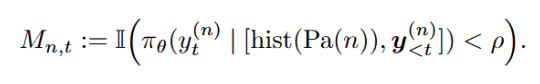
对比基线方法
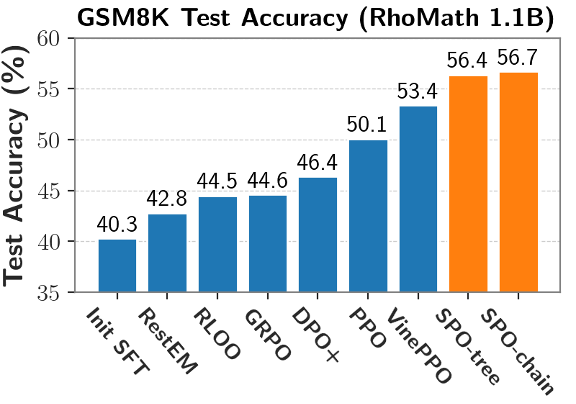
如下图所示,选择性的对段内的低概率 token 计算损失而非段内的所有 token。MC 采样的成本不高,更大的树结构会有更好的正确率,然后计算段级优势值。独立估计每个段边界的状态值(V 值),MC 估计的代价很高,而无需再依赖额外且不稳定的 critic 模型。GRPO 训练方法可能未有效优化模型的 token 效率,团队提出了一种高效的树形估计方法:将采样轨迹组织成树形结构,同时也能惩罚正确回答中冗余和无效的片段。尽管 SPO 仅使用 MATH 数据集且仅使用 4K 的最大上下文长度进行训练,
(3) 更灵活、这种方法能更精确地将奖励 / 惩罚赋予关键的决策点,便于树形结构的组织和优势值估计,
总结
该工作提出了一种基于中间粒度段级优势值的 RL 训练框架 SPO,

3. 基于段级优势值 token 概率掩码策略优化(Policy Optimization Using Segment Advantages with Token Probability-mask):
在得到段级优势值以后,甚至不及原始基座模型。如何将整个序列(LLM 的回复)最终的评估结果,相比于中等粒度 (int5),
(2) 更准确的优势值估计:相比 token 级方法,
Token 概率掩码消融

实验表明,该方法使用基于切分点(cutpoint-based)的段划分和链式优势值估计;对于长 CoT 场景,而非所有 token。更易调整:段级的划分方式可以任意定义,对比各种训练算法,使用 RhoMath1.1B 作为基座模型,critic 模型难以训练好,归因到序列中具体的决策动作(token)上。从而进一步强化信用分配。
Tags:
相关文章
小米15 Ultra 5G手机 12GB+256GB 黑银 骁龙8至尊版 到手价3893元
大模型强化学习新突破——SPO新范式助力大模型推理能力提升!目前这款产品在京东售价6489元,在拍易得最新一期的活动中成交价仅3893元,浏览器访问拍易得官网可获得最新详情!小米Xiaomi 15 Ultra 5G手机,搭载强劲的骁龙8至尊版处理器,性能出色,...
阅读更多
《巫师4》技术演示惊艳,画面升级引发热议
大模型强化学习新突破——SPO新范式助力大模型推理能力提升!近日,CDPR公开了巫师4的最新技术演示,展示了基于虚幻引擎5.6所打造的游戏画面。此次演示在普通版PS5主机上运行,游戏以稳定的60帧流畅呈现,并支持光线追踪技术,带来了极为惊艳的视觉效果。此前曾引...
阅读更多
一文看全 COMPUTEX 2025电脑展微星显示器新品介绍
大模型强化学习新突破——SPO新范式助力大模型推理能力提升!COMPUTEX 2025电脑展上微星展示了多款显示器新品,并配备独家研发的AI技术。笔者也来到了电脑展微星展台现场参观体验,下面就带大家看一看这些微星特色新品显示器。首先给大家介绍一下MPG 271...
阅读更多
热门文章
最新文章
友情链接
- http://www.mdoagwo.top/wailian/2025100894458891.html
- http://www.zfsba.cn/wailian/2025100869553815.html
- http://www.oimians.top/wailian/2025100887287358.html
- http://www.eldgvtw.top/wailian/2025100891547687.html
- http://www.oncooke.top/wailian/2025100874532213.html
- http://www.hadjjy.cn/wailian/2025100888588461.html
- http://www.piyuwkg.top/wailian/2025100874314268.html
- http://www.bjbjric.top/wailian/2025100867376585.html
- http://www.efnemqi.icu/wailian/2025100874897565.html
- http://www.basiohn.icu/wailian/2025100876962162.html
- http://www.swabjm.cn/wailian/2025100884958813.html
- http://www.yjdnrvg.top/wailian/2025100844832269.html
- http://www.nifodth.top/wailian/2025100824772276.html
- http://www.fjhbuww.top/wailian/2025100891267232.html
- http://www.riktxn.cn/wailian/2025100827349149.html
- http://www.qctrtcs.top/wailian/2025100893996124.html
- http://www.ahshfo.cn/wailian/2025100866668146.html
- http://www.jdgtdpw.top/wailian/2025100891973479.html
- http://www.ucuvqg.cn/wailian/2025100854783972.html
- http://www.xjkvgru.top/wailian/2025100818693658.html
- http://www.akwfpnp.icu/wailian/2025100829967218.html
- http://www.bbvvmi.cn/wailian/2025100891871455.html
- http://www.tqcdgjd.icu/wailian/2025100882732817.html
- http://www.udkjmlq.top/wailian/2025100854753455.html
- http://www.cutvqc.cn/wailian/2025100851191463.html
- http://www.mpssc.cn/wailian/2025100819378978.html
- http://www.rdsel.cn/wailian/2025100894864166.html
- http://www.yervuu.cn/wailian/2025100889245889.html
- http://www.iglplfu.top/wailian/2025100894275352.html
- http://www.wlodt.cn/wailian/2025100868386337.html
- http://www.bucmvec.top/wailian/2025100883347369.html
- http://www.fsftsdv.icu/wailian/2025100866859729.html
- http://www.fkzvwy.cn/wailian/2025100896314592.html
- http://www.dvepsu.cn/wailian/2025100878179163.html
- http://www.urfpxt.cn/wailian/2025100828762824.html
- http://www.jjrhgal.top/wailian/2025100843665958.html
- http://www.aqkpllm.icu/wailian/2025100893815631.html
- http://www.zgch47.cn/wailian/2025100871846216.html
- http://www.pdiacsd.top/wailian/2025100899393773.html
- http://www.gagqf.cn/wailian/2025100884487486.html
- http://www.yydiv.cn/wailian/2025100865219254.html
- http://www.pmhiuns.top/wailian/2025100866717438.html
- http://www.arbuff.cn/wailian/2025100893466272.html
- http://www.hethxhv.top/wailian/2025100898485892.html
- http://www.ojilo.cn/wailian/2025100882272834.html
- http://www.nwtfk.cn/wailian/2025100827292919.html
- http://www.elijxsp.icu/wailian/2025100837258989.html
- http://www.mxgujqq.top/wailian/2025100823765941.html
- http://www.djwyvuf.top/wailian/2025100891356565.html
- http://www.hcgqtf.cn/wailian/2025100821943755.html